(Non-exhaustive) Test of low-code / autoML solutions
Jan 24, 2023

Introduction
In recent years, there has been a lot of discussion about the future of data science and the role of automation in the field. Specifically, there have been predictions that the use of "auto ML" or "low-code" solutions would eventually make traditional data science work obsolete.
With this in mind, we decided to take a closer look at the current state of the market and investigate the various low-code and autoML solutions that are currently available. To do this, we used a publicly available Kaggle dataset of lead scores and tested over 10 different solutions.
Throughout the process, we kept an open and honest record of our experiences using each solution and attempted to build a classification model using the data. We wanted to see if the predictions of the future of data science had come true or not.
TLDR
The only low-code solution that was looking promising was AWS Canvas
While it ultimately did not work for our specific use case, we were impressed by its analytics and feature selection capabilities.
If Amazon were to improve the user interface and user experience of Canvas, and make it available outside of the AWS ecosystem (i.e don’t make people set-up an AWS account), we believe it could become a clear leader in the low-code ML space.
AutoML libraries like pycaret and h2o were a very nice surprise. Worked seamlessly and you get a great performance out-of-the-box on our tabular dataset
MindsDB was the greatest surprise of all, a different paradigm (ML on data layer), and worked flawlessly without any data cleaning or data formatting issues. It will definitely be our go-to for rapid prototyping.
The review
Preamble
In our evaluation of low-code and autoML solutions, we aimed to keep our analysis concise by providing a pros and cons list for each solution tested. The problem we set out to solve using these solutions was straightforward. We used a Kaggle dataset for lead scoring, which can be found at https://www.kaggle.com/datasets/amritachatterjee09/lead-scoring-dataset.
The dataset, however, was not as straightforward. It was dirty with a lot of textual features and missing data, making it a more realistic representation of a real-world dataset. The learning problem we aimed to solve was a multi-label classification, where we had to use all of our features to predict the "Lead Quality" feature. The possible values for this feature were: ['Not Sure', 'Low in Relevance', 'Might be', 'Worst', 'High in Relevance'].
To gain a complete understanding of the dataset, we referred to an exploratory data analysis done by the dataset owner.
For our analysis, we tried to input the raw dataset with no transformations at first. And when that was not possible, we performed as few transformations as possible, usually just encoding the target feature.
Obviously.ai
Pros:
UI is pretty
It was fast (after I had to stop to clean the data target)
Cons:
No (or minimal) support for preprocessing data
A lot of blockers stopped the workflow (I get it, I am using the free version, but nevertheless the placement of so many blockers is off-putting)
No connection to other databases → If I want to use the data I would need to export it manually and add it to my data source or write a script to do it
Weak prediction results
Review:
One of the key benefits of this solution is its user interface, which is visually pleasing and easy to navigate. Additionally, the solution was relatively fast, although this may have been due to the fact that we had to perform some data cleaning before getting started.
On the other hand, there were a number of downsides to this solution. One of the most notable was the lack of support for preprocessing data. We had to do a little bit of formatting and encode the target feature (i.e. Lead quality) to a numerical encoding to proceed.

When training, your AI model went through a 5-fold cross-validation process. A subset of data was used to test for performance.

To launch/deploy the model there is an endpoint available or you can launch the mini-app/form.

One last thing that we want to mention is that there were a lot of blockers that stopped the workflow, which was very frustrating for us. This may be more of an issue with the free version of the solution (hopefully the paid version does not ask for feedback every 5 min), but the placement of so many blockers is still off-putting.
Another problem with this solution is that it does not have a connection to other databases. This means that if you want to use the data, you would need to export it manually and add it to your data source or write a script to do it. Finally, the prediction results were relatively weak (compared to the other solutions below), which is a significant concern for any data science practitioner.
Levity
Pros:
Seems to be the player in the space that is betting the most on integrations (which makes sense)
Cons:
UX was still clunky, we were presented during the app flow with a lot of problems with boilerplates but no easy way to do the classification task with ingested data (i.e. custom task)
UI also was broken, could not load the dataset and keep my journey
Could not train a model
Also, what is this block for “non-work” emails… I get it, but it’s off-putting
Review:
One of the main advantages of this solution is that it seems to be the player in the space that is betting the most on integrations, which makes sense given the nature of the product. This could be a great advantage for users looking for a solution that easily integrates with other tools and platforms.
However, there were also a number of downsides to this solution. One of the most notable was the clunky user experience. We were presented with a lot of problems with boilerplates during the app flow, but there was no easy way to perform the classification task with ingested data (i.e. custom task).
I choose the best use case there that was similar to mine, but then there was I again lost (to be open, there were plenty of signs and pop-ups to take me to schedule a call with them, but I’m in a rush…).
After that, the UI was also broken and we were unable to load the dataset or continue our journey and train the model.
To be fair, I believe this is the wrong tool because I think it's more about classification based on text or image, and not a general auto ml platform. I am sure the example cases work, but I could not move forward with my data, so we stopped here.
Another issue with this solution was a block for "non-work" emails. While it's understandable why this feature may be included, it's still off-putting. Overall, while the integration focus is a plus, the clunky UX, broken UI, and inability to train a model, in the end, make it difficult to recommend this solution.
Google automl (i.e. Vertex A.I.)
Pros:
Seems easy at first to ingest data and start training (if you already have a GCP account)
Cons:
Almost no control over training/execution
Training did not respect the time budget and kept going
No model trained in the end
Review:
One of the main advantages of this solution is that it seems easy at first to ingest data and start training, especially if you already have a GCP account.
However, there were also a number of downsides to this solution. One of the most notable was the lack of control over training and execution. We had almost no control over how many models were going to be trained, which made it difficult to understand what was going on under the hood.

Trying the raw data did not work, I believe the pre-processing step is very weak (or non-existent). Took almost 10 minutes to show that “Labels cannot contain \r, \n or be empty”.
After encoding the target feature, we tried to train a new model. This time it went through but the worst part here is that the training did not respect the time budget. Why do we need to set up a budget beforehand if it is totally ignored during the execution? After almost two hours of training, we canceled it.

Pycaret
Pros:
Installation was straightforward and good to go with two lines of code. Beauty.
Good support for automated preprocessing
Has integration for cloud deployment with fastapi and also gradio for quick app demo!
Cons:
Need to run on notebooks (trying running on the terminal and you get hanged on the need to respond to prompts and etc)
Review:
One of the main advantages of this solution is that the installation process was straightforward and easy to set up with just two lines of code. This is a great advantage for users looking for a quick and easy solution to get started with machine learning.
Another advantage is the good support for automated preprocessing. The solution has good support for preprocessing which makes it easy for users to clean and prepare their data for training (the first one so far).
We loaded the encoded dataset (i.e ”target cleaned”) and after 30-min or so, we had our results.
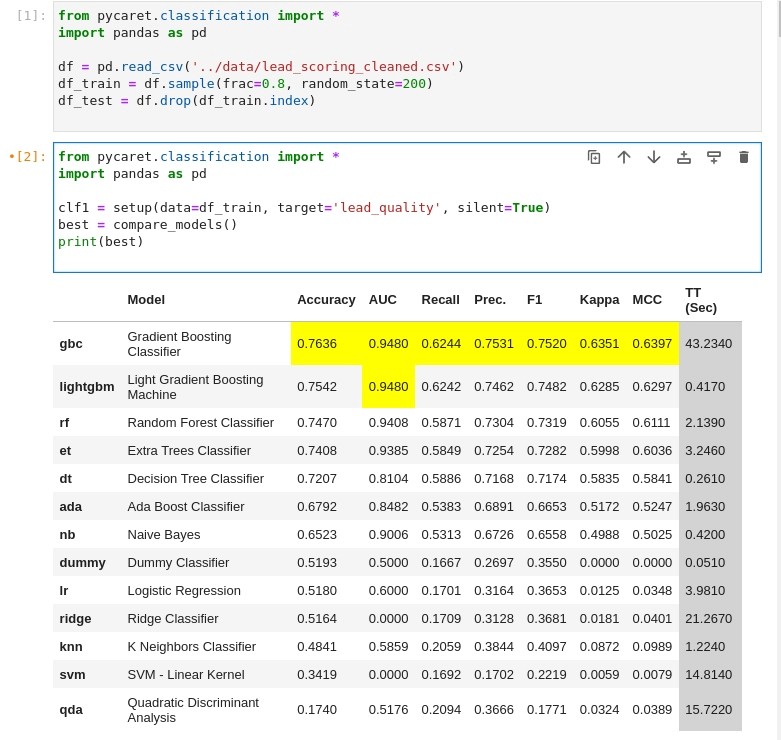
Overall experience was very good (and with good performance too!).
A good plus here also is that the solution has integration for cloud deployment with fastapi and gradio for quick app demo which makes it easy for users to deploy their models. This is a great feature for users who want to easily make their models available to others.
One of the main drawbacks that we found is that it was made to run on notebooks (trying to run on the terminal can lead to hanging on the need to respond to prompts and etc). This can be a problem for users who prefer to work outside of notebooks. Overall, while the installation process and preprocessing support are a major plus, the need to run on notebooks can be a drawback for some users.
H2O AutoML
Pros:
Easy installation
Model results in a couple of lines
Good performance out of the box
Big platform containing sister frameworks available that were built by H2O
Cons:
Have to dig their API and docs to use their product
Minimal support for “auto” pre-processing
Review:
One of the main advantages of this solution is that the installation process is easy, making it a great option for users looking for a quick and easy solution to get started with machine learning.
Another advantage is that the solution provides good performance out of the box, which allows users to get model results in just a couple of lines of code. This is a great feature for users who want to spend less time on model building and more on data cleaning and preprocessing.
Additionally, the solution is part of a big platform that contains sister frameworks available that were built by H2O. This makes it easy for users to access additional resources and support, which can be a great advantage for users who are new to machine learning.
Despite these advantages, there are some downsides to this solution. One of the main drawbacks is that users have to dig through the API and documentation to use the product. This can be a problem for users who are new to machine learning and are not familiar with the API and docs. Additionally, there is minimal support for “auto” pre-processing which can be a problem for users who want to spend more time on model building and less on data cleaning. Overall, while the easy installation and good performance out of the box are major plus, the need to dig through the API and docs and minimal support for pre-processing can be a drawback for some users.


Ludwig
Declarative machine learning: End-to-end machine learning pipelines using simple and flexible data-driven configurations.
Pros:
Powerful declarative structure
Cons:
Troublesome to debug (errors do not show straightforward helpful messages)
Could not make the auto ml API work given broken ray dependencies
Needs a lot of configuring and manual intervention to get good results
Review:
Could not get the autoML API working, and went for the manual setup of the configuration via yaml.
Initial results were bad (14% accuracy), but I believe that tweaking the config and letting it run for more time would yield better results
MindsDB
Pros:
Easy to set up, worked flawlessly
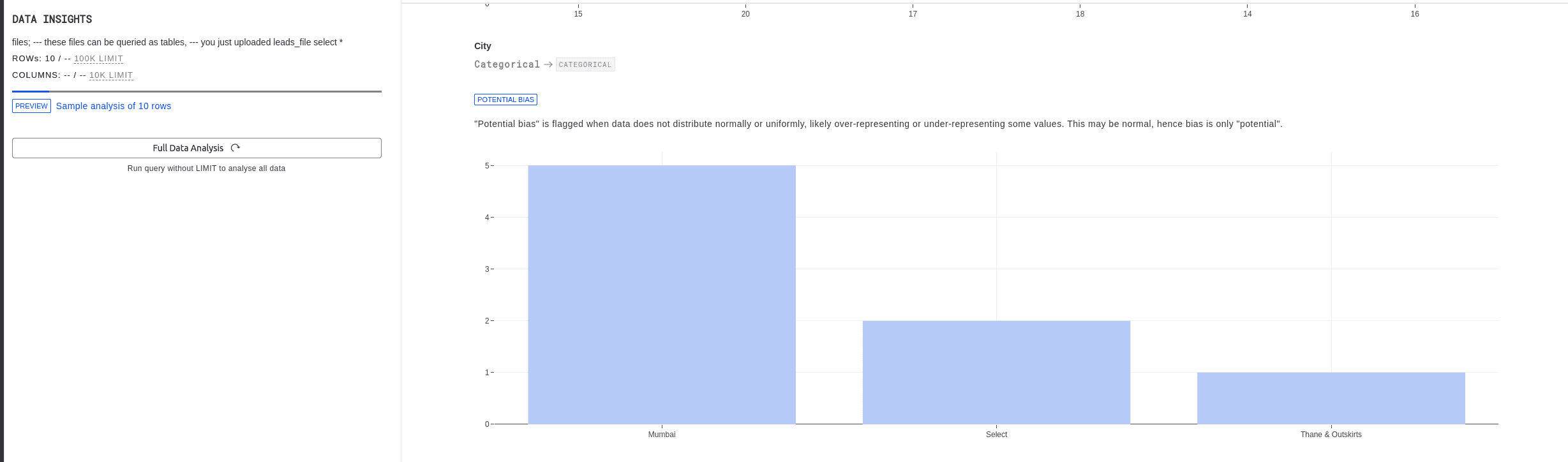
Automatic data analysis and processing - no need to clean data prior + automatic distribution plots
Fast training and good accuracy
Cons:
Not clear if it can handle images (although there is a handle to use Ludwig, that can take image encoders)
Doubts on scalability here (no benchmarks with high loads of data) (to be fair, if one is going big with a lot of data, then it's better to have a robust architecture)
Review:
MindsDB was a great surprise for us. It was easy to set up, and it worked flawlessly. The automatic data analysis and processing feature was a huge plus as it eliminated the need for us to clean the data prior to training. Additionally, automatic distribution plots provided a quick way to understand the data.
The training was fast, and the accuracy was good. This is a great solution for rapid prototyping.
While MindsDB handled tabular data well, it was not clear if it could handle images. Although there is a handle to use Ludwig, which can take image encoders, we did not test it.
We have some doubts about scalability, as we did not see any benchmarks with high loads of data. However, it's important to note that if one is going big with a lot of data, then a robust architecture is probably a better option.
PostgresML
Pros:
Benchmark looks good and I believe that it is promising for the future
Easy setup with docker
Cons:
Was unable to upload the dataset to their cloud demo dashboard
No support for data cleaning/transformation
No out-of-box support for categorical variables
Could not train the model there even with manual pre-processing (got some non-informative rust error)
API seems way clunkier and underdeveloped than Mindsdb
Dashboard notebook is very unfriendly to use, better to use native psgcli
Review:
Benchmark looks good and I believe that it is promising for the future. But despite the good benchmark, we were unable to upload the dataset to their cloud demo dashboard. This made it difficult to test the platform and evaluate its capabilities.
There was no support for data cleaning or transformation, which is a highly desirable feature here. The platform also lacked out-of-box support for categorical variables, which made it difficult to work with our dataset out-of-the-box.
Despite our efforts to adapt the dataset, we were unable to train the model. We encountered a non-informative rust error at the end that made it impossible to proceed.
The API seemed clunkier and underdeveloped yet.
The dashboard notebook was also very unfriendly to use (why not create a plugin for jupyter?). We found it much easier to use the native psgcli instead. Overall, the project shows promising results but it is still very underdeveloped.
AWS Canvas
Pros:
The only “low-code” ML that looked polished
Fair pre-processing and pre-analysis
Cons:
Long time to set up everything (create an AWS account, create SageMaker env, set up credentials, set canvas env…)
Canvas upload did not work even with the correct authorization to upload data (I had to go straight to S3 to upload files)
It’s AWS, everything is way more difficult than it needs to be (especially deleting used resources… I spent more time trying to delete resources than doing the ML stuff). The complexity of the AWS ecosystem can be a barrier for some users, especially those who are new to the platform.
The process of uploading data and getting started with the platform was quite cumbersome, even with the promise of a "low-code" experience.
Deleting resources used in the process of training and deploying models can also be time-consuming and difficult.
The lack of seamless integration with other tools and services can also be a limitation for some users.
Review:
Canvas is part of Amazon’s SageMaker - which is a platform for developing and deploying machine learning models.
The twist for Canva is that is advertised as a low-code ML tool (for data analysts?). Despite the difficulties in setting up and using the platform, these features are worth exploring for those who are already familiar with SageMaker (and AWS in general). However, for users who are new to the platform and looking for a more user-friendly solution, the added complexity of the AWS ecosystem may not be worth it.
Navigating the AWS ecosystem is sometimes painful, and this is the case setting up Canvas. I am not sure if their target audience would invest their time in learning their way around AWS. The onboarding experience here can be definitely improved.
In terms of the tool itself, it looks very polished and it has some promising pre-processing and pre-analysis features. We were able to use the raw dataset, while their pre-processing engine took care of the parsing, feature removal, and additional processing steps. Also shows feature-target correlations and the features’ distribution.


Once you finish reviewing the data, Canva performs a preview of the expected performance results. For our dataset, we were getting around 78% accuracy. The problem is when we actively tried to train the model. Canva just broke and we just got a “request failed” pop-up to contact support.

From the “low-code” platforms, Canva seems the most polished one. Major drawbacks are the time cost to set-up everything up and the training problem that we had.